Amazon OpenSearch Service is a fully managed service that reduces operational overhead, provides enterprise-grade security, high availability, and scalability, and enables you to quickly deploy real-time search, analytics, and generative AI applications. OpenSearch itself is an open-source, distributed search and analytics suite that supports a wide range of use cases, including real-time monitoring, log analytics, and full-text search. OpenSearch Service offers zero-ETL integrations with other Amazon Web Service (AWS) services, enabling seamless data access and analysis without the need for maintaining complex data pipelines.
Zero-ETL refers to a set of integrations designed to minimize or eliminate the need to build traditional extract, transform, load (ETL) pipelines. Traditional ETL processes can be time-consuming and difficult to develop, maintain, and scale. In contrast, zero-ETL integrations allow direct, point-to-point data movement and can also support querying across data silos without physically moving the data.
In this post, we explore various zero-ETL integrations available with OpenSearch Service that can help you accelerate innovation and improve operational efficiency. We cover following types of integrations, their key features, architecture, benefits, pricing, limitation and some general best practices.
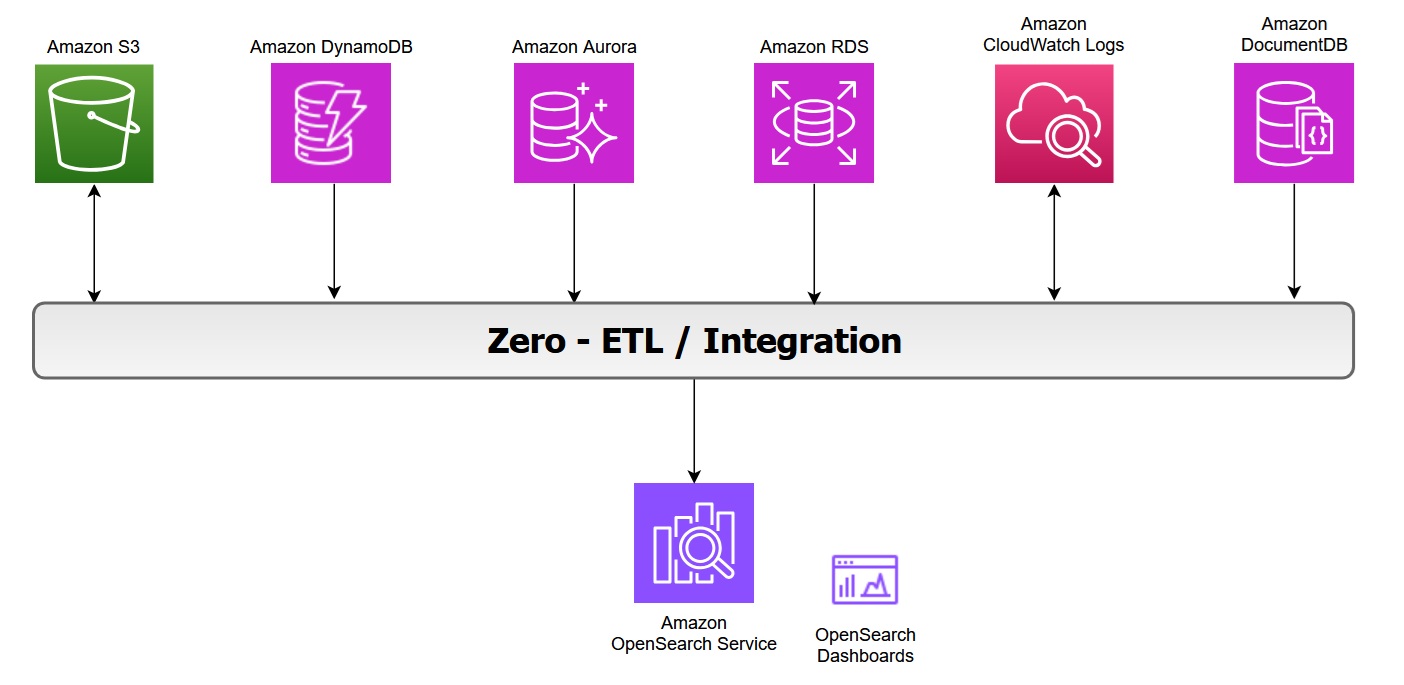
The following diagram illustrates the zero-ETL integration architecture in AWS, showing how various AWS services feed data into OpenSearch Service and its associated dashboards:
Amazon OpenSearch Service direct queries with Amazon S3 provides a zero-ETL integration to reduce the operational complexity of duplicating data or managing multiple analytics tools by enabling you to directly query their operational data, reducing costs and time to action.
Key features of this integration include:
The zero-ETL integration with Amazon S3 supports OpenSearch Service. For more information on architecture and feature see the post Modernize your data observability with Amazon OpenSearch Service zero-ETL integration with Amazon S3.
In log analytics use cases, we categorize operational log data into two types:
You can offload infrequently queried data, such as archival or compliance data, to Amazon S3. With direct query, you can analyze analytics from Amazon S3 without data movement or duplication. However, query performance in OpenSearch Service might slow down when you’re accessing external data sources due to factors like network latency, data transformation, or large data volumes. You can optimize your query performance by using OpenSearch indexes, such as a skipping index, covering index, or materialized view.
While Amazon S3 direct query integration with OpenSearch Service provides on-demand access to data stored in Amazon S3, it is important to remember that OpenSearch’s alerting, monitoring, anomaly detection, and security analytics capabilities can only operate on data that has been explicitly ingested into OpenSearch Service indices. These capabilities would not work with direct query with Amazon S3. However, it will work if the data is indexed with covering or materialized index.
With direct queries with Amazon S3, you no longer need to build complex ETL pipelines or incur the expense of duplicating data in both OpenSearch Service and Amazon S3 storage. You also save time and effort by not having to move back and forth between different tools during your analysis.
OpenSearch Service separately charges for the compute needed to query your external data in addition to maintaining indexes in OpenSearch Service. Costs for Direct Query is based on the data volume scanned, query execution time, query frequency and frequency with which the indexed data in OpenSearch is kept updated. For more information, see Amazon OpenSearch Service Pricing.
In case you are using OpenSearch service to query directly data on Amazon S3, consider the limitations with Direct Query.
These are some general and Amazon S3 recommendations for using direct queries in OpenSearch Service. For more information, see Recommendations for using direct queries in Amazon OpenSearch Service.
Amazon CloudWatch Logs serves as a centralized monitoring and storage solution for log files generated across various AWS services. This unified logging service offers a highly scalable platform where all your logging data converges into one manageable system. It provides comprehensive functionality for log management, including real-time viewing, pattern searching, field-based filtering, and secure archival capabilities. By presenting all logs chronologically in a unified stream, CloudWatch Logs eliminates the complexity of managing multiple log sources, transforming diverse logging data into a coherent, time-ordered sequence of events.
The zero-ETL integration between Amazon CloudWatch and Amazon OpenSearch Service enables direct log analysis and visualization while avoiding data redundancy, thereby reducing both technical complexity and costs. You can now leverage two additional query languages alongside the existing CloudWatch Logs Insights QL when using CloudWatch Logs, while as an OpenSearch user, you gain the ability to query CloudWatch logs directly.
Review New Amazon CloudWatch and Amazon OpenSearch Service launch an integrated analytics experience, to explore how the integration works between OpenSearch Service and Amazon CloudWatch Logs.
When you use OpenSearch Service direct queries, you incur separate charges for OpenSearch Service and the resource used to process and store your data on Amazon CloudWatch Logs. As you run direct queries, you see charges for OpenSearch Compute Units (OCUs) per hour, listed as DirectQuery OCU usage type on your bill.
You can find a pricing example on running an OpenSearch dashboard from either OpenSearch UI or CloudWatch Logs (pricing example n°7).
For more pricing information, see Amazon OpenSearch Service Direct Query pricing.
In addition to the OpenSearch Service “direct queries” general limitations, if you are direct querying data in CloudWatch Logs, the following limitations apply:
Besides the general recommendations of OpenSearch Service direct querying, when using OpenSearch Service to direct query data in CloudWatch Logs, the following is recommended:
Amazon DynamoDB zero-ETL integration with OpenSearch Service lets you perform a search on your DynamoDB data by automatically replicating and transforming it without custom code or infrastructure. This zero-ETL integration uses Amazon OpenSearch Ingestion to synchronize data between Amazon DynamoDB and OpenSearch Service cluster or OpenSearch Serverless collection within seconds of it being available.
It uses DynamoDB export to Amazon S3 to create an initial snapshot to load into OpenSearch Service. After the snapshot has been loaded, the plugin uses DynamoDB Streams to replicate any further changes in near real time. Turn on point-in-time recovery (PITR) for export and the DynamoDB Streams feature for ongoing replication.
This feature allows you to capture item-level changes in your table and push the changes to a stream. Every item in tables is processed as an event in OpenSearch Ingestion and can be modified with processors. You can also specify index mapping templates within ingestion pipelines to ensure that your Amazon DynamoDB fields are mapped to the correct fields in your OpenSearch indices.
To learn more, see DynamoDB zero-ETL integration with Amazon OpenSearch Service in the AWS documentation.
When configuring zero-ETL between DynamoDB and OpenSearch Service, consider the differences between the data models. You have the following options with data layout:
You can achieve this by using the conditional routing feature in the OpenSearch ingestion pipeline.
There is no additional cost to use this feature apart from the cost of the existing underlying components, including OpenSearch Ingestion charges OpenSearch Compute Units (OCUs) which is used to replicate data between Amazon DynamoDB and OpenSearch Service. Furthermore, this feature uses Amazon DynamoDB Streams for the change data capture (CDC), and you incur the standard costs for Amazon DynamoDB Streams.
Consider the following limitations when you set up an OpenSearch Ingestion pipeline for DynamoDB:
For complete information, see Best practices for working with DynamoDB zero-ETL integration and OpenSearch Service
Amazon RDS and Amazon Aurora integration with OpenSearch Service eliminates complex data pipelines and enables near real-time data synchronization between Amazon Aurora and Amazon RDS databases (including RDS for MySQL and RDS for PostgreSQL) with advanced search capabilities on transactional databases. You can use an OpenSearch Ingestion pipeline with Amazon RDS or Amazon Aurora to export existing data and stream changes (such as create, update, and delete) to OpenSearch Service domains and collections. The OpenSearch Ingestion pipeline incorporates change data capture (CDC) infrastructure to provide a high-scale, low-latency way to continuously stream data from Amazon RDS or Amazon Aurora.
This automated process keeps your data consistently up to date in OpenSearch Service, making it readily available for search and analysis purpose. The pipeline ensures data consistency by continuously polling or receiving changes from the Amazon Aurora cluster or Amazon RDS and updating the corresponding documents in the OpenSearch index. OpenSearch Ingestion supports end-to-end acknowledgement to ensure data durability. An OpenSearch Ingestion pipeline also maps incoming event actions into corresponding bulk indexing actions to help ingest documents. This keeps data consistent, so that every data change in Amazon RDS is reconciled with the corresponding document changes in OpenSearch.
For details on the architecture, refer to Integrating Amazon OpenSearch Ingestion with Amazon RDS and Amazon Aurora. To get started, refer to OpenSearch Ingestion pipeline with Amazon RDS or Using an OpenSearch Ingestion pipeline with Amazon Aurora.
There is no additional charge for using this feature beyond the cost of your existing underlying resources, such as OpenSearch Service, OpenSearch Ingestion pipelines (OCUs), and Amazon RDS or Amazon Aurora. Additional costs may include storage used for enabling enhanced binlogs for MySQL and WAL logs for PostgreSQL for change data capture. You also incur storage costs for snapshot exports from your database to Amazon S3 used for the initial data.
Consider the following limitations when you set up the integration for Amazon RDS or Amazon Aurora:
The following are some best practices to follow while setting up the integration with OpenSearch Service:
Amazon Document DB is a fully managed database service built for JSON data management at scale. It offers built-in text and vector search functionalities. By leveraging OpenSearch Service, you can execute search analytics, including features like fuzzy matching, synonym detection, cross-collection queries, and multilingual search capabilities on DocumentDB data.
The zero-ETL integration initiates the process with a full historical data extraction to OpenSearch using an ingestion pipeline. After the initial data load is completed, the pipelines read from Amazon DocumentDB change streams ensuring near real-time data consistency between the two systems. OpenSearch organizes the incoming data into indexes, with flexibility to either consolidate data from a DocumentDB collection into a single index or partition data across multiple indices. The ingestion pipelines synchronize all create, update, and delete operations from the DocumentDB collection, maintaining corresponding document modifications in OpenSearch. This ensures both data systems remain synchronised.
The pipelines offer configurable routing options, allowing data from a single collection to be written to one index or conditionally route to multiple indexes. Users can configure ingestion pipelines to stream data from Amazon DocumentDB to OpenSearch Service through three primary modes namely full load only, streaming change events without initial full load and full load followed by change streams. You can also monitor the state of ingestion pipelines in the OpenSearch service console. Additionally, you can use Amazon Cloudwatch to provide real-time metrics and logs and setting up alerts.
There is no additional charge for using this feature apart from the cost of your existing underlying resources, including OpenSearch Service, OpenSearch Ingestion pipelines (OCUs), and Amazon DocumentDB. The integration performs an initial full load of Amazon DocumentDB data and continuously streams ongoing changes to OpenSearch Service using change streams. The change streams feature is disabled by default and does not incur any additional charges until the feature is enabled. Using change streams on a DocumentDB cluster incurs additional read and write input/output (I/O), as well as storage costs.
To learn more on pricing see the DocumentDB pricing page.
The following are the limitations for the DocumentDB to OpenSearch Service integration:
The following are some best practices to follow while setting up the DocumentDB zero-ETL with OpenSearch Service:
To get started, see zero-ETL integration of Amazon DocumentDB with OpenSearch Service.
With zero-ETL integrations, you can use the powerful search and analytics features of OpenSearch Service directly on your latest database data. These include full-text search, fuzzy search, auto-complete, and vector search for machine learning (ML) workloads—enabling intelligent, real-time experiences that enhance your applications and improve user satisfaction. This integration uses change streams to automate the synchronisation of transactional data from Amazon Aurora, Amazon RDS, Amazon DynamoDB and Amazon DocumentDB to OpenSearch Service without manual intervention. Once the data is available in OpenSearch Service, you can perform real-time searches to quickly retrieve relevant results for your applications.This eliminates the need for manual Extract-Transform-Load (ETL) processes, reduces operational complexity, and accelerates time-to-insight for real-time dashboards, search, and analytics.
In this post, you learned that zero-ETL integrations represent a significant advancement in simplifying data analytics workflows and reducing operational complexity. As you’ve explored throughout this post, these integrations offer several advantages such as elimination of complex ETL pipelines and reduced infrastructure and operational costs by removing the need for intermediate storage and processing that enhance developer productivity.
It is time to accelerate your analytics journey with OpenSearch Service zero ETL – where your data flows seamlessly, eliminating complex pipelines and delivering real-time insights. Get started with Amazon OpenSearch Service or learn more about integrations with other services and applications in the AWS documentation.
Omama is GTM Specialist Solutions Architect Analytics at Amazon Web Services. She focuses on helping customers across various industries build reliable, scalable, and efficient solutions. Outside of work, she enjoys spending time with her family, listening to music, and learning new technologies.
Canberk is an Associate Solutions Architect at Amazon Web Services, helping software companies achieve their business goals by leveraging AWS technologies. He is part of OpenSearch specialist community within AWS and has been guiding customers harness the power of OpenSearch. Outside of work, he enjoys sports, reading, traveling and playing video games.







