This post is part 3 of the three-part series ‘Enabling high availability of Amazon EC2 instances on AWS Outposts servers’. We provide you with code samples and considerations for implementing custom logic to automate Amazon Elastic Compute Cloud (EC2) relaunch on Outposts servers. This post focuses on guidance for using Outposts servers with third party storage for boot and data volumes, whereas part 1 and part 2 focus on automating EC2 relaunch between standalone servers. Outposts servers support integration with Dell PowerStore, HPE Alletra Storage MP B10000 systems, NetApp on-premises enterprise storage arrays, and Pure Storage FlashArray.
Outposts servers provide compute and networking services that are designed for low-latency, local data processing needs for on-premises locations such as retail stores, branch offices, healthcare provider locations, or environments that are space-constrained. Outposts servers use EC2 instance store storage to provide non-durable block-level storage to the instances running stateless workloads. For applications that require persistent storage, you can create a three-tier architecture by connecting your Outposts servers to a third-party storage appliance. In this post, you will learn how to implement custom logic to provide high availability (HA) for your applications running on Outposts servers using two or more servers for N+1 fault tolerance. The code provided is meant to help you get started, and can be modified further for your unique workload needs.
In the following sections we will show how custom logic can be used to automate EC2 instance relaunch between two or more Outposts servers using boot and data volumes on third party storage. If your EC2 instance fails while using this solution, an Amazon CloudWatch alarm monitoring the EC2 StatusCheckFailed_Instance metric of your source EC2 instance will be triggered, and you will receive an Amazon Simple Notification Service (Amazon SNS) notification. An AWS Lambda function will then relaunch your EC2 instance onto the destination Outposts server that you’ve set up for resiliency. This is done using a launch template created during setup, and the script will connect your relaunched instance to the existing boot and data volumes on your third party storage appliance. This storage device provides shared storage for your Outposts servers. If a single server fails, new instances can connect to existing volumes on the array. This allows for a zero data loss Recovery Point Objective (RPO) and a Recovery Time Objective (RTO) equaling the time it takes to launch your EC2 instance. Take advantage of the features on your storage appliance for configuring data durability and resiliency to hardware failures, and make sure that you are regularly backing up your SAN volumes.
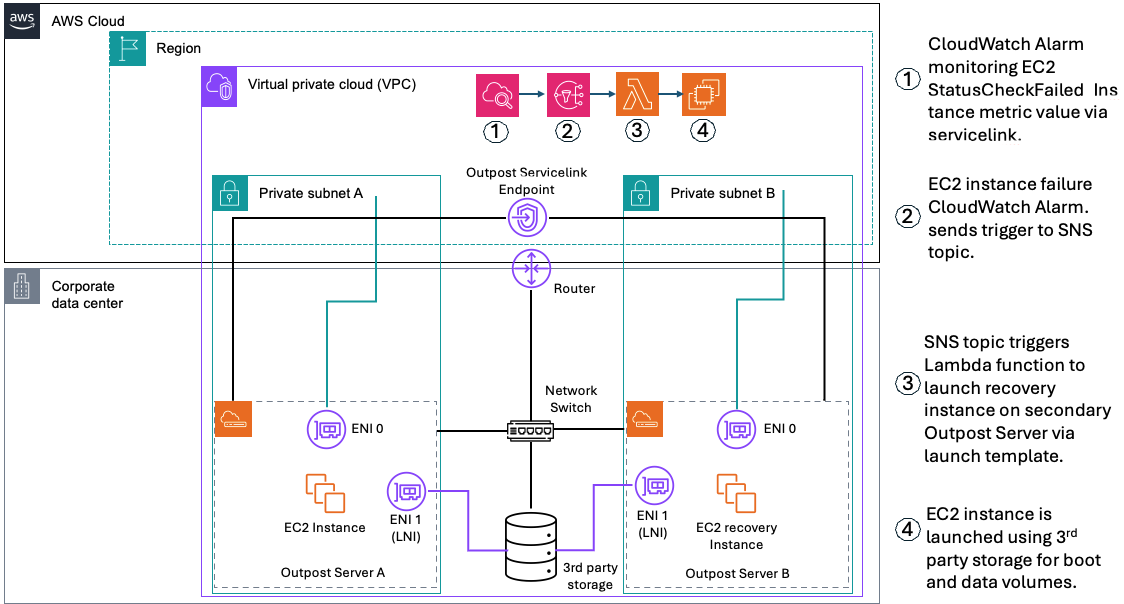
Figure 1 – Solution Architecture for automated EC2 Relaunch
The following prerequisites are required to complete the walkthrough:
The first step is to deploy an EC2 instance configured to boot from a volume on the third-party storage that is prepared with an OS boot image. This step uses the launch wizard portion of the solution.
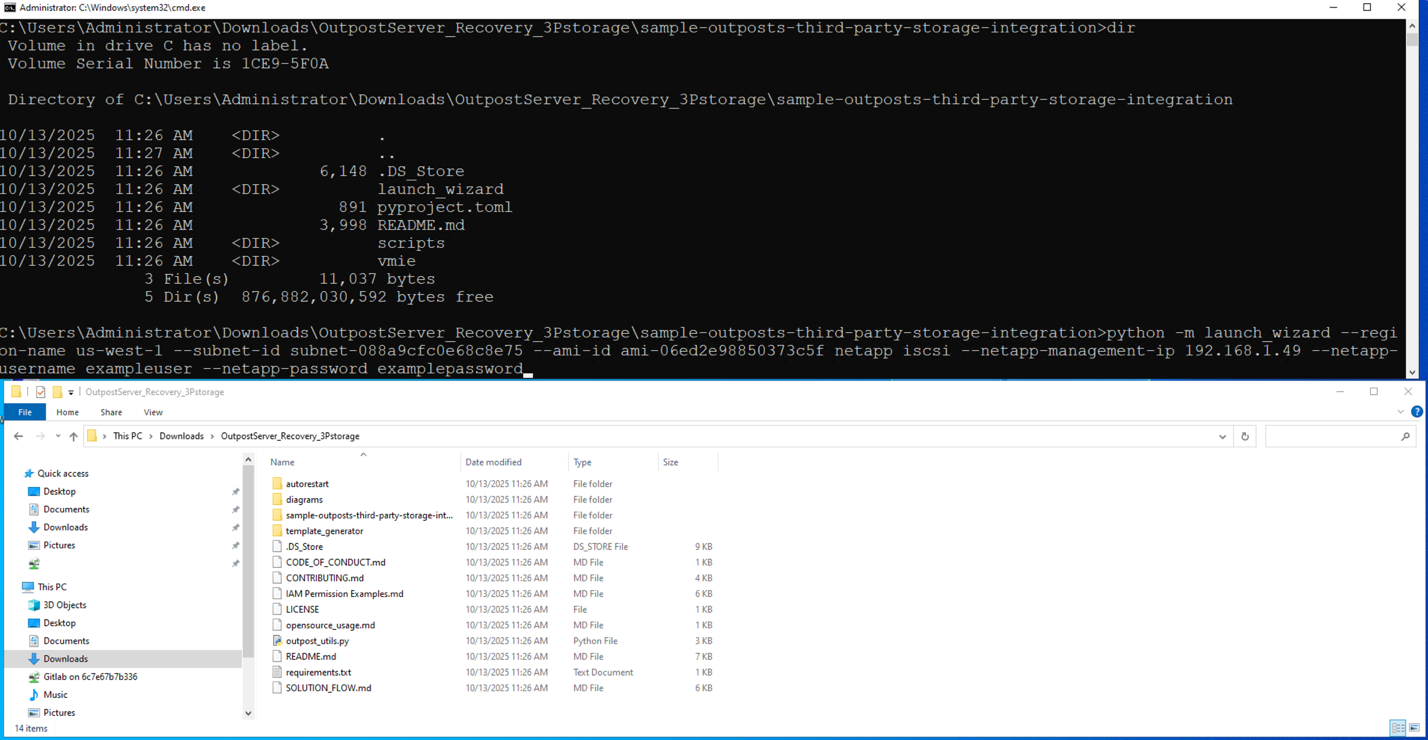
Figure 2 – Running launch wizard

Figure 3 – Taking user input for variable values

Figure 4 – Running launch template creation script
In the second step, we are generating EC2 launch templates for the EC2 instance launched in step 1. Launch templates can be generated for the primary and secondary Outpost servers. The launch template for the secondary Outpost server can be used for automated or manual recovery of the EC2 instance. Failback to the primary Outpost server is manual using the primary launch template.
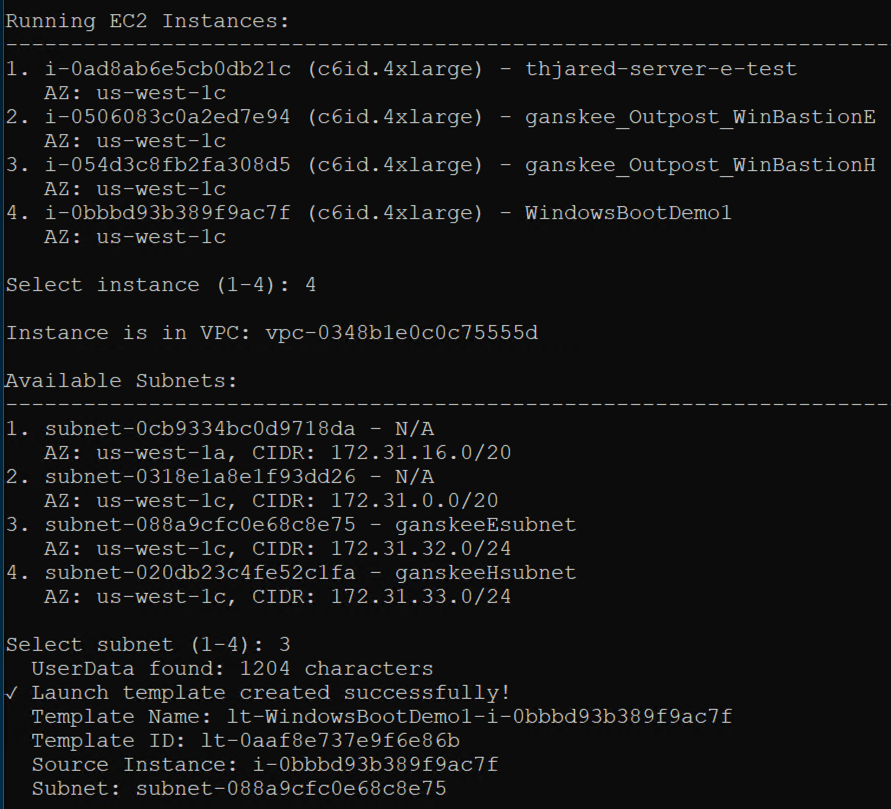
Figure 5 – Selecting subnets for EC2 instance relaunch
The third step creates a CloudFormation template for monitoring, notifications, and automated recovery of the EC2 instance deployed in step 1. The CloudFormation template automatically captures the instance and secondary launch template information necessary for automatic recovery.

Figure 6 – CloudFormation stack creation in progress
The logic discussed in this post relies on the secondary destination Outposts server having a connected service link. For more information about how to create a highly available service link connection for your Outpost servers, see the Networking section of AWS Outposts High Availability Design and Architecture Considerations whitepaper.
Confirm whether it is safe to terminate the Amazon EC2 instance that you launched with this walkthrough. The operating system and data volumes are on the third party storage, so EC2 instance termination only removes the iPXE AMI from the Outposts server instance storage. To clean up, complete the following steps.
With the use of custom logic through AWS tools such as CloudFormation, CloudWatch, Amazon SNS, and AWS Lambda, you can architect for HA for stateful workloads on Outposts server. By implementing the custom logic in this post, you can automatically relaunch EC2 instances running on a source Outposts server to a secondary destination Outposts server if an instance fails, and connect to existing volumes on a shared storage appliance for recovery. This also reduces the downtime of your applications in the event of a hardware or service link failure. The code provided in this post can be further expanded upon to meet the unique needs of your workload.
While the use of infrastructure-as-code (IaC) can improve your application’s availability and be used to standardize deployments across multiple Outposts servers, it’s crucial to do regular failure drills to test the custom logic in place. This is to make sure that you understand your application’s expected behavior on relaunch in the event of a failure. To learn more about Outposts servers, visit the Outposts servers User Guide. Reach out to your AWS account team, or fill out this form to learn more about Outposts servers.







